
Published on 00/00/0000
Last updated on 00/00/0000
Published on 00/00/0000
Last updated on 00/00/0000
Share
Share
IN-DEPTH TECH
3 min read

Share
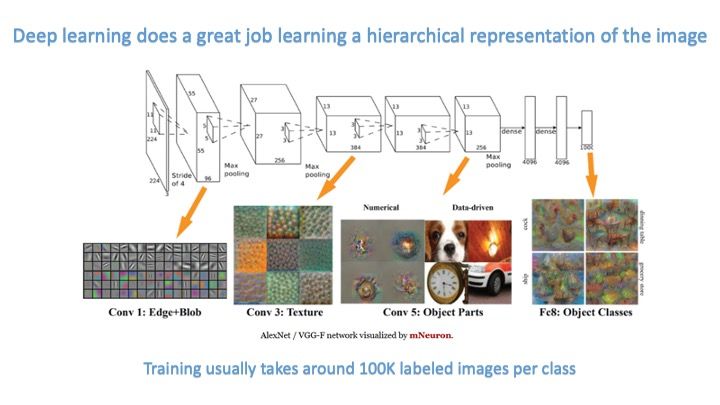 The hierarchical knowledge representations that DL learns have some similarities to those learned by animal and human brains. Fantastic! So what’s the problem?
The hierarchical knowledge representations that DL learns have some similarities to those learned by animal and human brains. Fantastic! So what’s the problem?
 The problem is that current DL algorithms tend to utilize only a few pixels to make the final classification decision. This means that even though DL models include deep hierarchical information, the ultimate performance of the DL classifier is based on a rather shallow knowledge representation. This is why it is easy to fool many DL algorithms with adversarial examples that can reliably turn a correct Stop Sign classification into a Speed Limit X classification. How can we improve this situation?
The problem is that current DL algorithms tend to utilize only a few pixels to make the final classification decision. This means that even though DL models include deep hierarchical information, the ultimate performance of the DL classifier is based on a rather shallow knowledge representation. This is why it is easy to fool many DL algorithms with adversarial examples that can reliably turn a correct Stop Sign classification into a Speed Limit X classification. How can we improve this situation?
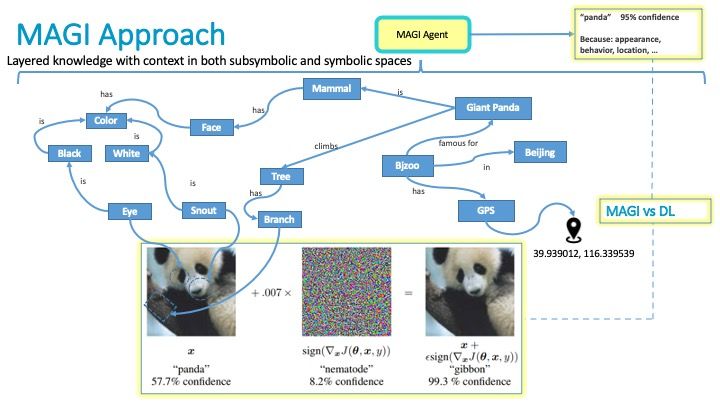 In a nutshell, by combining the deep hierarchical knowledge representation learned by the deep learning system with a symbolic knowledge representation. A quick google search for neurosymbolic or knowledge graph will yield many hits. We’ve learned a few things over the years about these sorts of neurosymbolic systems in practice which you can learn more about here: https://www.researchgate.net/project/A-Metamodel-and-Framework-For-AGI. In a word, we’ve learned that simply gluing together ML/DL and a knowledge graph is not quite enough. In order to achieve the holy grail “blessing of dimensionality”, you need to add some additional structure.
Our initial paper above is a good starting point for learning more about the nature of this additional structure. My plan is to cover the key points in a series of additional medium blogs. Of particular interest is that this additional structure appears to be beneficial to intelligences in general be they “natural” or “artificial”.
In a nutshell, by combining the deep hierarchical knowledge representation learned by the deep learning system with a symbolic knowledge representation. A quick google search for neurosymbolic or knowledge graph will yield many hits. We’ve learned a few things over the years about these sorts of neurosymbolic systems in practice which you can learn more about here: https://www.researchgate.net/project/A-Metamodel-and-Framework-For-AGI. In a word, we’ve learned that simply gluing together ML/DL and a knowledge graph is not quite enough. In order to achieve the holy grail “blessing of dimensionality”, you need to add some additional structure.
Our initial paper above is a good starting point for learning more about the nature of this additional structure. My plan is to cover the key points in a series of additional medium blogs. Of particular interest is that this additional structure appears to be beneficial to intelligences in general be they “natural” or “artificial”.
Get emerging insights on innovative technology straight to your inbox.
Outshift is leading the way in building an open, interoperable, agent-first, quantum-safe infrastructure for the future of artificial intelligence.

* No email required
The Shift is Outshift’s exclusive newsletter.
Get the latest news and updates on agentic AI, quantum, next-gen infra, and other groundbreaking innovations shaping the future of technology straight to your inbox.




